Building Ubuntu for the Raspberry Pi
As a result of the prior musings about crowdfunding and the rather shaky VAT status of the whole sector I have been thinking quite a bit about crowdfunding and where it might be useful and how we could get involved in some way. For our normal consultancy business we have no need of capital investments and we don’t produce anything that lends itself to the crowdfunding model, however I did come up with a project I have been wanting to do for quite a long time. Allow me to introduce it by way of a little video . . .
Back when the Raspberry Pi was in development it was shown running Ubuntu 9.04, Jaunty Jackalope. This was the last Ubuntu release that supported the ARMv6 instruction set, from that point on Ubuntu was optimised for newer ARM chips and would not run on the Broadcom chip that the Pi used. I am the point of contact of the Ubuntu UK Local Community team and I was dead excited about this little computer with it’s exposed PCB and low price point. I asked some of the Ubuntu ARM folk if they could support it going forward, but that wasn’t going to be possible, they didn’t have the resources to build for two ARM platforms and the bottom line was that the Pi probably wasn’t going to provide a good user experience for the increasingly heavy Ubuntu user interface. This was sad, but it was the situation. I was a bit concerned that the Raspberry Pi foundation was proceeding on the basis that Jaunty was available – it was already old, going out of support and was a dead end, there were going to be no future updates for it. I was concerned that the UK Local community was going to be landed with a lot of new users who were having a poor user experience and there would be nothing we could do about it. Reluctantly I approached the Raspberry Pi foundation (I met the lovely Liz and Eben at an event in Oxford) and shared my concerns with them, and suggested Debian was the way forward, so the Pi would have a system based on a platform Ubuntu users would be familiar with, that would get updates.
So this was sad, I wasn’t happy about it, the foundation wasn’t happy about it, many users were not happy about it, but it was much better to have a new Debian with updates and prospects than an old dead end Ubuntu release.
Moving on to the present, the Raspberry Pi is a huge success, Rasbian is a great operating platform for it, the LXDE desktop is fine, the Wayland demo was brilliant and loads of cool projects are happening based on the Pi. We still want Ubuntu on it though. We are using it in embedded projects, it is also turning up in things like the OpenERP Point of Sale kit, situations where it doesn’t need a responsive user interface (or a user interface at all). It would be great to know that all the libraries we are using on it are the same versions we are using on other computers that are running Ubuntu. It might be nice to see what the Ubuntu Unity desktop looks like on the Pi, especially Unity 8 running in Mir, but that explicitly isn’t a goal. This project aims to build everything that will build from source without too much hassle. If that gets us a desktop then great, if it gets us a command line with python, that is great too.
Now for the armchair accountants in the audience, having seen the admin end of a campaign I can explain it a little better than before. This is a flexible funding setup rather than the all-or-nothing option and we are accepting paypal and credit card pledges. The paypal pledges happen instantly, the money goes from the end user direct to our paypal account and then there is an immediate debit of 9% of the amount which goes from us to indiegogo – so the money is not held in escrow at all, and it isn’t a big payment at the end. This is fairly clearly a purchase of a pledge to the full pledge value and a subsequent payment to indiegogo which is either a purchase of campaign hosting services, or some kind of financial services fee, not sure about that bit yet. Credit card payments are slightly different, we don’t have the money for those yet, after the campaign ends Indiegogo will do a bank transfer to us for the funds (less the 4% or 9% commission presumably). Paypal is regulated as a bank now, so I think the money should turn up in our financials when it is in the paypal account, not just when we make a transfer of it to a bricks and mortar bank. We will enter all the pledges as sales and pay VAT on them and we will reclaim the VAT on the materials purchased to build the cluster. If anyone wants a VAT invoice for a paypal pledge I can sort that out. Credit card pledges are a bit more interesting as it is questionable whether they have happened yet.
If you want to contribute to the cluster and help us build Ubuntu for the Raspberry Pi then do head on over to Indiegogo and join the 40 or so other contributors we have so far.
From the technical side of things, designing the cluster feel free to pitch in your comments and suggestions below. We have had a lot of people suggesting that we don’t use the Raspberry Pi and use some other platform instead. These suggestions include: cross compile it from Intel machines, use QEMU on fast Intel computers, use cloud computing, use a Power Mac (whut!), use the OpenSUSE Build Service, Use a Calxeda box, use Pandaboards, use Wandboard quad core arm boards. Feel free to add to the list of other platforms we should be using instead, I think I will add the yet to be delivered Parallela board to the list of things we should be using. All these suggestions are great, they would work and they might even be faster or easier. They just are not things I really want (apart from the Parallela which I don’t have) and I don’t think it works as a crowdfunding concept to raise funds to build it out of anything but the Raspberry Pi.
To provide power to lots of Pis there are a few approaches, Southampton University did this:

and other cluster projects have build custom 5v electronics for feeding the USB or direct to the GPIO pins. The custom supply option doesn’t work out particularly cheap and to run the whole cluster you are looking at parts of the circuit supporting a current heading towards 32 amps, which gets kinda complicated. At the moment I am leaning towards using a special powered hub, the Pihub which can cope with powering 4 Pi devices from a single slightly beefy supply. This keeps the plug count down (they will all need PAT testing at some point so I don’t want to go completely wild on plugs) and keeps everything neat and safe and fanless.
Networking is another area where there are options. WiFi sounds mad for a cluster, but is it really? The Pi Ethernet port kind of hangs off USB internally, so wouldn’t a 150Mbit USB wifi dongle be comparable to a 100Mbit ethernet? Lets solve this using science. Initial testing with iperf shows 74Mbit throughput on the ethernet between two Pi devices, over WiFi just 20Mbit. This is rather less than I would expect, maybe there is more performance that can be teased out of the wifi, or maybe the initial feeling is right and ethernet is the way forward. Maybe you have an opinion or advice in this area?
The funding campaign runs through to Christmas but as we have some of the money available already I am thinking we will probably start getting some bits fairly soon and start setting up the cluster controllers and do some power measurements and more detailed performance testing.
Crowdfunding and VAT
The trendy way to get your investment capital these days is to put together a slick video and shove your concept on Indiegogo or Kickstarter. You offer some gifts/rewards for different pledge levels and set an overall funding target and then sit back as everyone talks about it and does your advertising for you for free. Awesome stuff. It has been used for different types of project, often for bringing a bit of hardware from a prototype into production, and the pledge often includes one of the products – but there is an element of risk to it, some are delayed like the Parallela (which we funded, still waiting for our two boards) and some like The Doom That Came To Atlantic City and Clang appear to take a lot of money and deliver nothing. Some don’t meet the funding target, the most spectacular example of this was the Ubuntu Edge which managed to break the records for the most money pledged and the biggest shortfall at the same time, which is quite a clever trick. I was contemplating backing the Edge, but I certainly didn’t want to put it on my personal credit card, I wanted to put it through as a company expense – it would have been an interesting toy for us to play with. Libertus is a VAT registered company, this means we charge VAT on things we sell to our customers, and we reclaim VAT on stuff we purchase from suppliers – it is a “Value Added” tax not a sales tax. We pay tax on the value we add to the goods in the supply chain. This makes a lot of sense in a products business where you buy raw materials, do some process to them, and sell finished goods, but it also works just fine when we sell services and buy assorted bits and pieces that are not strictly raw materials. The upshot of this is that as a VAT registered business, when we buy pretty much anything, we can reclaim the 20% VAT that our supplier added in the price. So, back to crowdfunding, I asked Canonical if I would get a VAT receipt for the £430 or so that it would cost me for the phone, so I could reclaim the £71.66 VAT (or offset it against my VAT on sales, you don’t actually get money back from HMRC unless something is going very wrong in your business). The answer was no, they don’t issue VAT receipts, which kind of makes sense, sort of. It isn’t a product purchase, it isn’t an investment (there are lots of rules about what an “investment” is, and this isn’t one) it is basically an at-risk donation. So I can’t reclaim VAT on it. On the other side, is it a sale? Does the supplier have to remit VAT to their tax authority on the sale. Well, probably. You can’t just wriggle out of VAT by trading exclusively on a crowdfunding basis. Tax fiddles don’t work, they can look at the substance of what is happening even if the details are a bit dubious. If it walks like a sale, and it quacks like a sale then the tax authorities will want their slice of the party.
The other twist to this is that the major crowdfunding platforms are based outside Europe, Kickstarter is in New York, Â Indiegogo in San Francisco. The USA has state level sales taxes, and no VAT. The platforms are a party to the sale, you pay your money into their account, it is held in escrow for a bit, then released to the project with a percentage fee deduction. How does this affect the sale, am I purchasing the gift from the USA? Is there import duty now? Does this exempt it from VAT in some way or not?
This week our friends at OpenERP have launched their own crowdfunding campaign for a retail Point of Sale solution, based on our favourite little computer – the Raspberry Pi, and some other bits of hardware.

OpenERP Point of Sale
This is a cool project, I have been wanting to put together all these bits for some time, I bought a receipt printer and barcode scanner for development/demo purposes, but I don’t have a cash register and I have not had time to write the ESC/POS driver for the printer. This project will do the driver for the receipts properly and it assembles a set of reference hardware that can be reliably supported by OpenERP, which means we can help open up the retail sector to Free Software from the point of sale through to manufacturing, logistics, accounting and everything else. In short, this is great, I want it and it is a totally legitimate business expense for us – but I would really like to know how we account for the VAT element. Normally for a purchase from Belgium we would do reverse charge VAT, we notionally add 20% to it, then reclaim that back again, so there isn’t much net impact, but I have no idea if I need to do that on a crowdfunding pledge. Do comment if you have any thoughts on the matter!
Announcing ExceptionalEmails.com
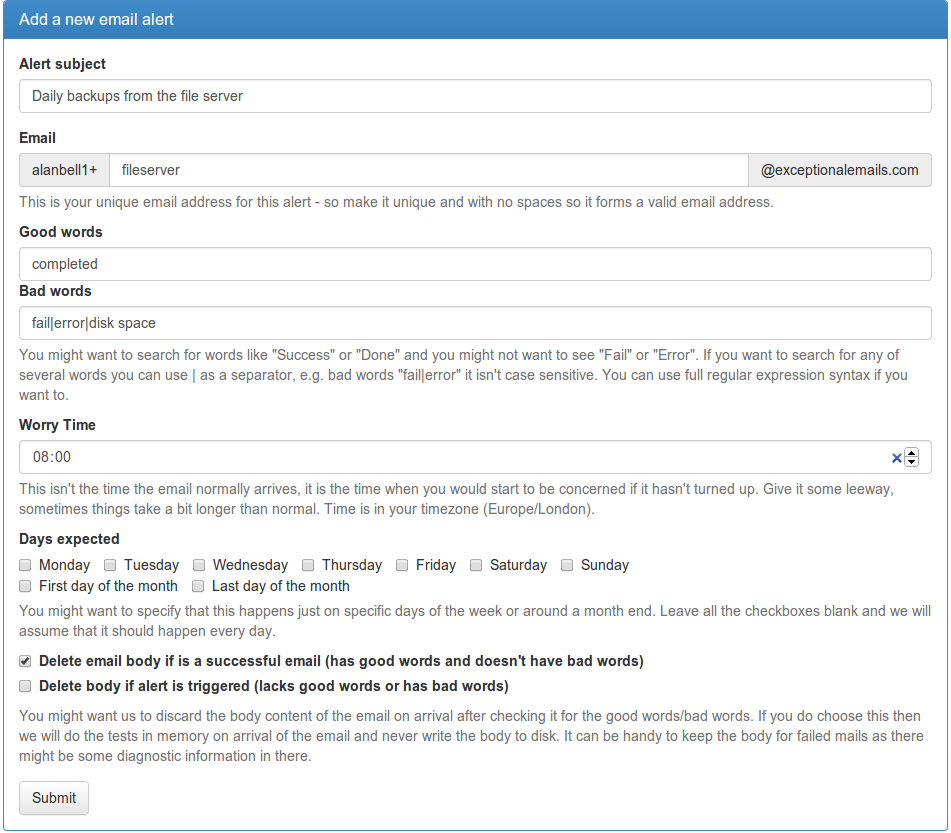
If you are a sysadmin or developer or similar you probably get a bunch of emails from systems telling you they are doing just fine. You probably have mail rules to shove these off into some folder you never look at so you can get on with life. If one should happen to not turn up, that would be kind of interesting, but there is no email rule you can make to alert you about an email that didn’t happen. Over the last couple of weeks I have been building a system to fix that http://exceptionalemails.com. You basically shove all the emails you get at a set of special email addresses, one for each type of regular email, and set up rules saying what you expect to happen. You then get on with your life, and if an email fails to happen, or perhaps contains the wrong words (fail/error/out of disk space/etc.) then and only then we will send you an email – you only need to see the exceptions.
This is the form to set up the rules for an alert, so in this example I would set my fileserver backup schedule to email alanbell1+fileserver@exceptionalemails.com when it is done (or leave it emailing me, and set up a rule to put the mail in a folder of my email and forward the mail to alanbell1+fileserver@exceptionalemails.com)
This was my first project using MongoDB as a back end and I have been really impressed by it, I have a background in NoSQL and it all made sense to me in terms of performance expectations and optimisations. I load tested it with a million emails and it was still really fast. It is running on Ubuntu server, with a user interface is written in PHP. The back end jobs that receive emails and check for alerts going overdue are written in Python.
I would be really interested in any feedback on the site, I have some plans for improving the analysis of past emails with sparklines so you can see when failures happened, and maybe fluctuations of arrival times of emails. Any other suggestions would be welcome. There is an outside chance that I might write a JuJu charm for it – and probably do a bit of a refactoring of the code to make deployment easier. One of the reasons for choosing MongoDB at the back end and a separate process to receive the emails was to allow it to scale horizontally across a bunch of servers. Based on my load testing I couldn’t hammer it hard enough to slow things down noticeably so I am not sure my grand clustering plans are going to be required.
The code is on Github, under AGPL3 and I am tracking issues there.
Bier vandeStreek

A few days ago here at Libertus Towers we received a lovely gift from a friend in the Netherlands: Free Beer!
vandeStreek Beer is from
Two enhusiastic brothers from Utrecht, the Netherlands who enjoy tasteful craft beers. After several years brewing on a micro scale, we are now sharing our beers with the world.
Thankfully our friend, a brother of the two brewers above, knew our love of all things beer, and thought it would be a good idea to let us sample his siblings’ art…
There are two brews called BROEDERS and DARK ROAST.
After leaving them for a good session in my fridge I thought I’d start by cracking open a Broeders…
-

- Bottle, Opener & Beer Mat.


-

- Small head, but it lasted the duration.

I’m a big fan of very hoppy beers with a good bitter finish (think really good IPA) and this Broeders is right up there for me. The first taste thought I had on the palette was “nutty”, very nutty, then the hops kicked in followed by a gentle breeze of burnt caramel. The beer was lovely and dry, clean tasting, surprisingly refreshing for a beer of this strength, and the head, whilst not deep, kept it’s consistency right to the bottom of the glass.
Broeders a strong beer by UK standards at 6.3% ABV so probably not one you’d want to do a long session on, but the high alcohol content didn’t destroy the flavours unlike some high-strength beers tend to do.
Whilst I was drinking Broeders I did think that the finish (the length of time the flavour lingers afterwards) might be rather short but how wrong I was! When I tottered off to bed, probably a good hour or so after I’d finished the glass, that hoppy, nutty complex of flavours was still there; it seemed a shame to have to clean my teeth!
To conclude then, I really liked this beer. So if you fancy trying something different I’d recommend vandeStreek Broeders any day.
Next week I’ll give you my take on the Dark Roast. To be honest I’m not expecting to like it so much. I’ve never really liked dark beers, many seem to me to be too sweet and a bit “thick” & sickly. But hey ho – I’m not going to not drink it; that would just be rude wouldn’t it… 😉
Ubuntu Smart Scopes
A new feature of Ubuntu was discussed today (which is like an announcement but without overhyping it), it is called Smart Scopes and is documented here https://wiki.ubuntu.com/SmartScopes1304Spec go read that first and then I have a video for you to watch.
http://www.youtube.com/watch?feature=player_embedded&v=CBeQur7VBDM
Now go back and read the spec that I told you to read earlier, but all the way to the end this time.
In the video from left to right is Alan Bell (me), David Callé, Jono Bacon, Michael Hall, Roberto Alsina and Stuart Langridge, all discussing this new framework for searching. It is coming soon, to the Ubuntu Raring desktop and then to phone and TV and tablet etc. The objective is to make searching really really effective and helpful to the user, but as with the previous efforts in this direction there will be some concerns around how it is implemented.
In short, Canonical will be running a server much like the existing productsearch.ubuntu.com server which will accept queries and return a bunch of results as json. The current implementation searches Amazon and the Ubuntu One music store and a few other places. The new one will do the same, plus more server-side searches, plus a new feature altogether which is a list of good scope names for the client to search. Your client will now send a list of all locally installed scopes to the server (actually a list of scopes you have added and a list of scopes you have removed or turned off from the standard set) along with your query. The server then returns results it found and wants to put in your dash, plus a subset of the local scopes you sent it, in order, that the server thinks would be good places to hunt for your search term. This means that your client might have 100 or more locally installed search scopes, but the server will advise it which are likely to give good results. Now for the scary bit, once you have looked at the results and perhaps clicked on something then your client pings the server again to tell it which scope produced the most relevant result. This means that the server can learn from this feedback about which scopes produce high quality results for that keyword, and perhaps rank that one a bit higher in future recommendations lists.
- Lenses are now called master scopes
- You control each individual scope that you want to search in or not search in, not the master scopes so you will have 100 or so things to turn on or off.
- You can still have locally installed scopes that search authenticated data sources
- You could in principal run your own search server if you write one to implement the API and patch the home master scope to look at your own server
- The server isn’t open source
- You can’t opt out of the feedback process (without turning off the smart scope altogether – which you can do)
- If you install a local scope then your client will tell the server the name of that scope
- Every query to the server is going to include a list of locally installed scope names (100 or so perhaps?)
- You can focus a search at a particular scope by using a keyword, for example “omlet: chicken house” to only search the Omlet scope and not the chicken stuff master scope.
- The rather poorly thought out remote-content-search checkbox to disable local scopes from doing online searches remains in place – however you don’t need it as you have per-scope controls.
- There may be some code quality checks introduced to stop scopes that don’t pay attention to the remote-content-search setting from getting into the Ubuntu distribution. – but you don’t need it.
- This probably won’t put more adverts on your desktop while you are trying to do work.
- This is probably a more private way of searching for stuff than googling for it.
- This won’t be opt-in, all the good stuff in Ubuntu is turned on by default.
- Your IP address gets logged on the web server logs, but not in the database of the smart scopes application running on the server. The developers working on the smart scopes don’t have access to the web server logs.
- It would be relatively trivial (I could do it in a day or so if I felt like it) to write a gnome-shell client for this smart scopes server to display the remote results, however doing something with the scope recommendations list would be a bit of a struggle.
- The home master scope (dash) search box will contain the help text “search your computer and online sources” to make it clear that it isn’t just a local search.
Now to the big question. How much are people going to freak out about this? Well if they read the spec all the way to the end they will see all the stuff that is being collected, how it is aggregated, how much or how little privacy this is costing them and why it is being done for the greater good of having decent search results. The feedback data collection process is likely to be slightly freakout causing. I can see why the developers want this turned on and I can see why it is antisocial to turn it off, like leeching on bittorrent while downloading an Ubuntu iso or whatever. I think they would be wise to have a checkbox in the privacy settings dialogue so that antisocial people can turn this off. I imagine the developers will stick with the current policy that if you want to use smart scopes you have to participate in the feedback process to make it better.
I think we need to do some education around the lack of an applications launcher though. Currently people think that Super + name of application is a replacement for the Gnome 2 applications menu. It isn’t. Super+a + name of application is how to start applications. This is going to focus the search on just applications and will work a lot faster than doing an omniglobaleverywhere search which is what the superkey does by itself.
For me this is a good development overall. The privacy debacle will be solved to my satisfaction when you can locally and personally blacklist scopes. This will mean that I can write a scope without it being co-dependent on all the other online scopes and I don’t have to worry about whether intranet access constitutes internet access. All scopes can simply stop if remote-content-search is set, but nobody needs to set it, the flag will basically just break all searching and be a bit pointless.
GeoTools: Geolocation services for vtiger CRM
As many of you know already, our company Libertus Solutions does quite a lot of work with the open source CRM called vtiger. It’s a very competent and accomplished product made even more so by its well thought out extension capabilities.
In this post I’m really pleased to announce our first open source vtlib module for vtiger called GeoTools.
It was derived from another project on the vtiger forge called Maps, which we have taken and extended in true open source style. Standing on the shoulders of giants, and all that…
GeoTools introduces Geolocation features to vtiger in a standard vtlib module package. It adds the ability to perform distance-based searches on your data.
GeoTools uses the Google Maps API to gather positional data, that’s latitude and longitude coordinates, for the entity records that have been configured in the GeoTools Settings area. Once we have acquired this positional data we can then perform location-based calculations to display the results on an embedded Google Map, and as a list view of entity records.
Anyway enough of the words already! Here’s a video:
As soon as the forge site is up I’ll update this and provide links to the code.
Update: Here we are: This will be a moving target for some time yet – it’s still rather “beta” grade code…

